











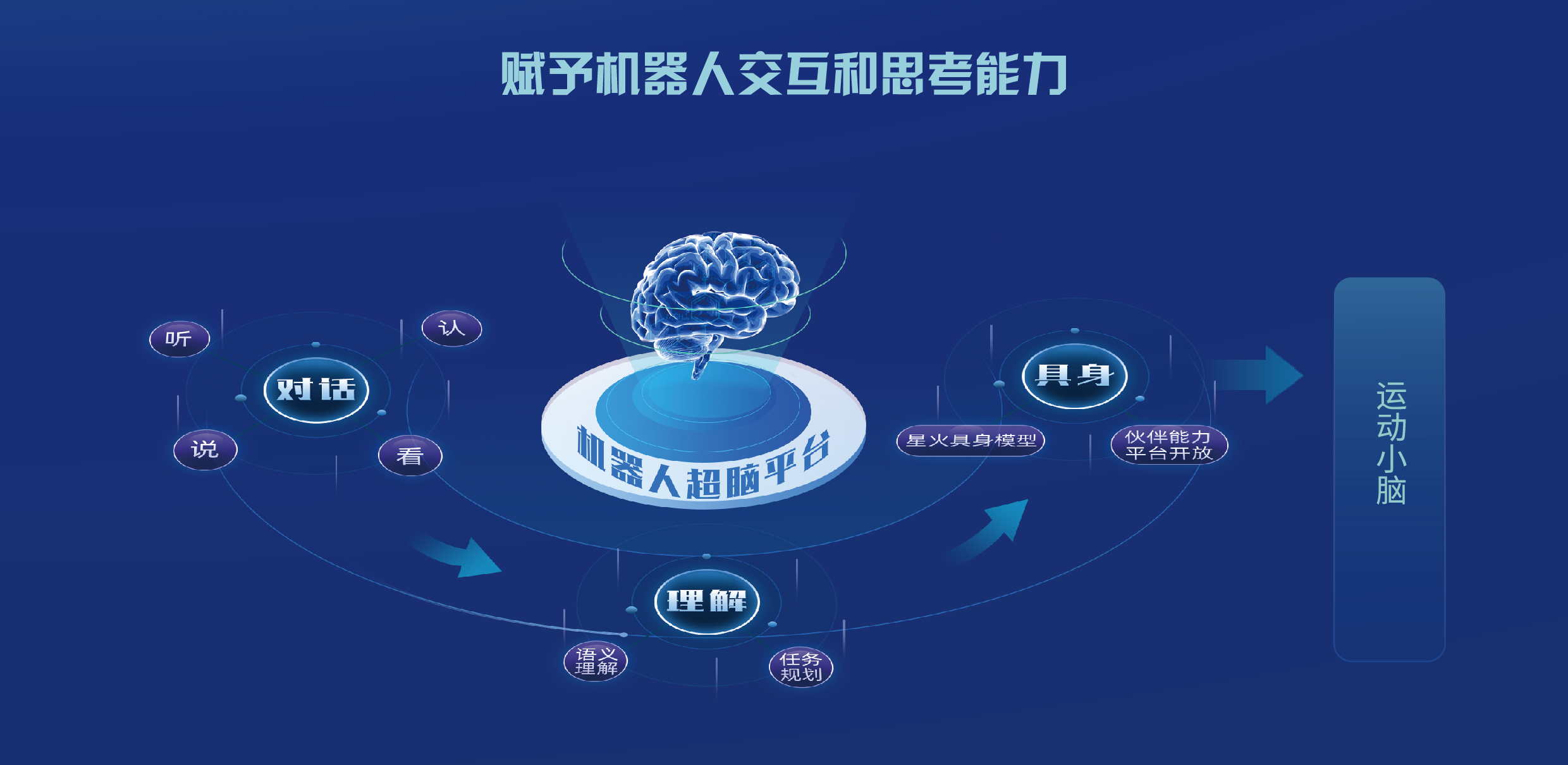
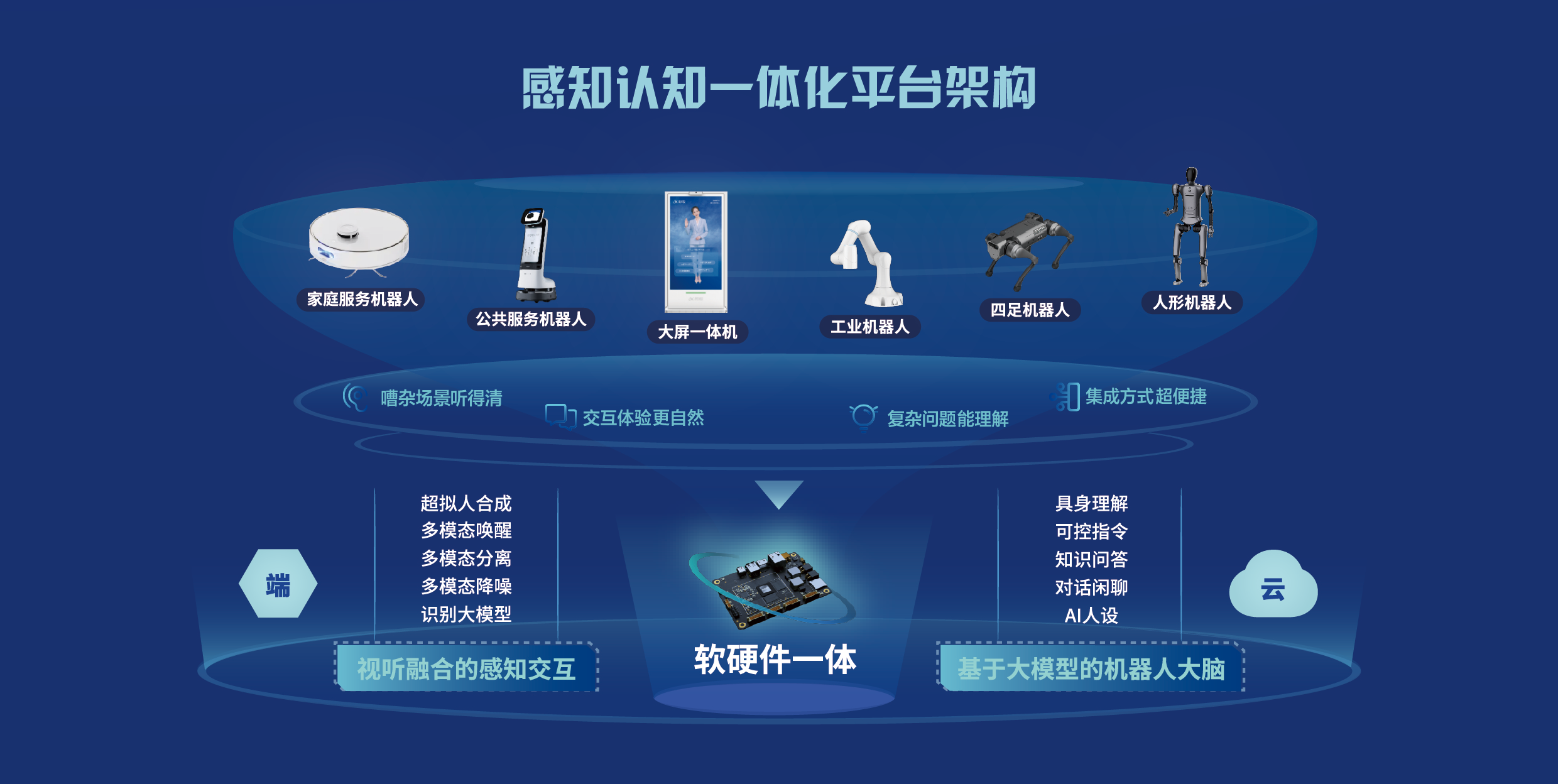
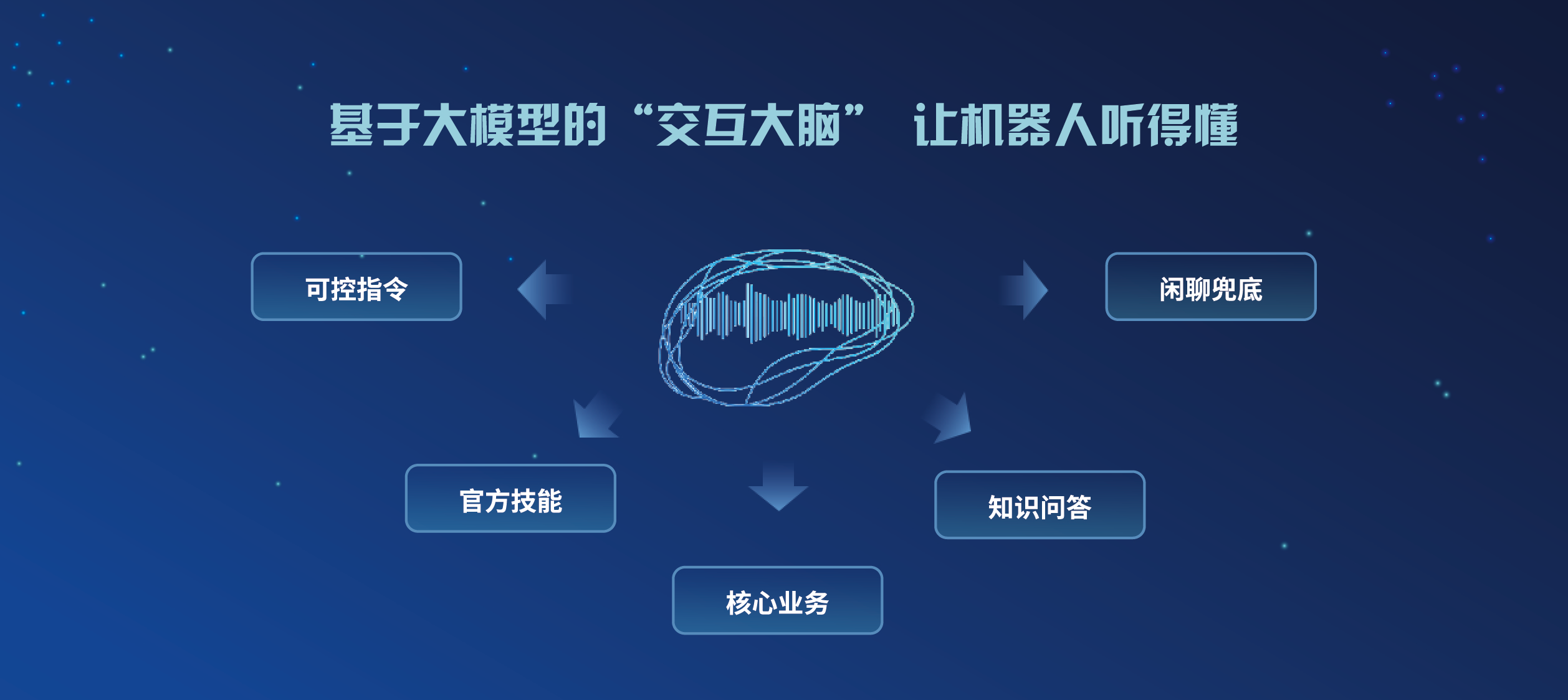
机器人超脑—多模态交互模块
产品亮点:无需唤醒词,人脸唤醒率99%; 同波束人声噪音下识别准确率94%; 多人语音分离准确率91%; 适合高噪音场景下机器人交互。










展品介绍
视听融合的感知交互,融合了语音、视觉、语义等多个维度的信息定义了包含开启交互、交互保持、切换交互权和结束交互在内的机器人交互新范式。人脸、唇形与语音信号相融合的多模态降噪,使得机器人能够在嘈杂、高噪场景下精准拾音,利用语音大模型和超拟人合成来促使机器人聊天更有生命力,声音复刻和高表现力的语音合成能够提升机器人对话的感染力。
